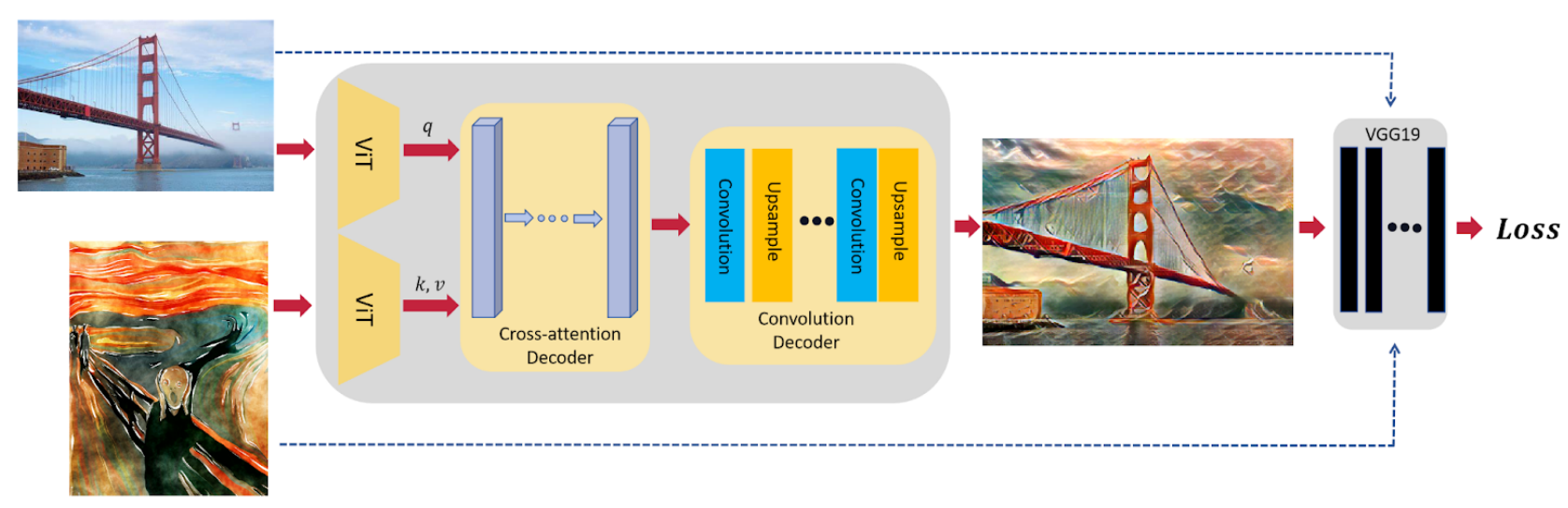
To improve the model perfomance in Neural Style Transfer (NST) tasks, we replaced the content and style encoders of StyTr2 with pre-trained ViT. Restricted by practical computation limitations, we leveraged a two-stage training strategy: we first froze the pre-trained ViT, just trained the decoders. Then we wrapped LoRA to fine-tune ViT with COCO datasets for joint training. By conducting extensive experiments, our contributions include: 1) Better image quality: through the incorporation of pretrained models and LoRA, our model performs better than other baselines in terms of both content loss and style loss, with the style loss nearly half of the baselines. 2) Less training computation: the two-stage training strategy reduces the required training computation significantly, only less than half of the training computation required by the original StyTr2 model. 3) Comprehensive ablation study: we have tried different sets of hyperparameters to explore how LoRA and the pretrained model configuration affect the model performance.

A comparison of generated images. To make the illustration easier, all images are resized into the same smaller size after image generation. Note that in the 4th row, where a large content image (3*1600*1064) of the Berkeley campus and a style of the Foxes are chosen, our model performs significantly better than other models, preserving the content details best and with a clear style.
