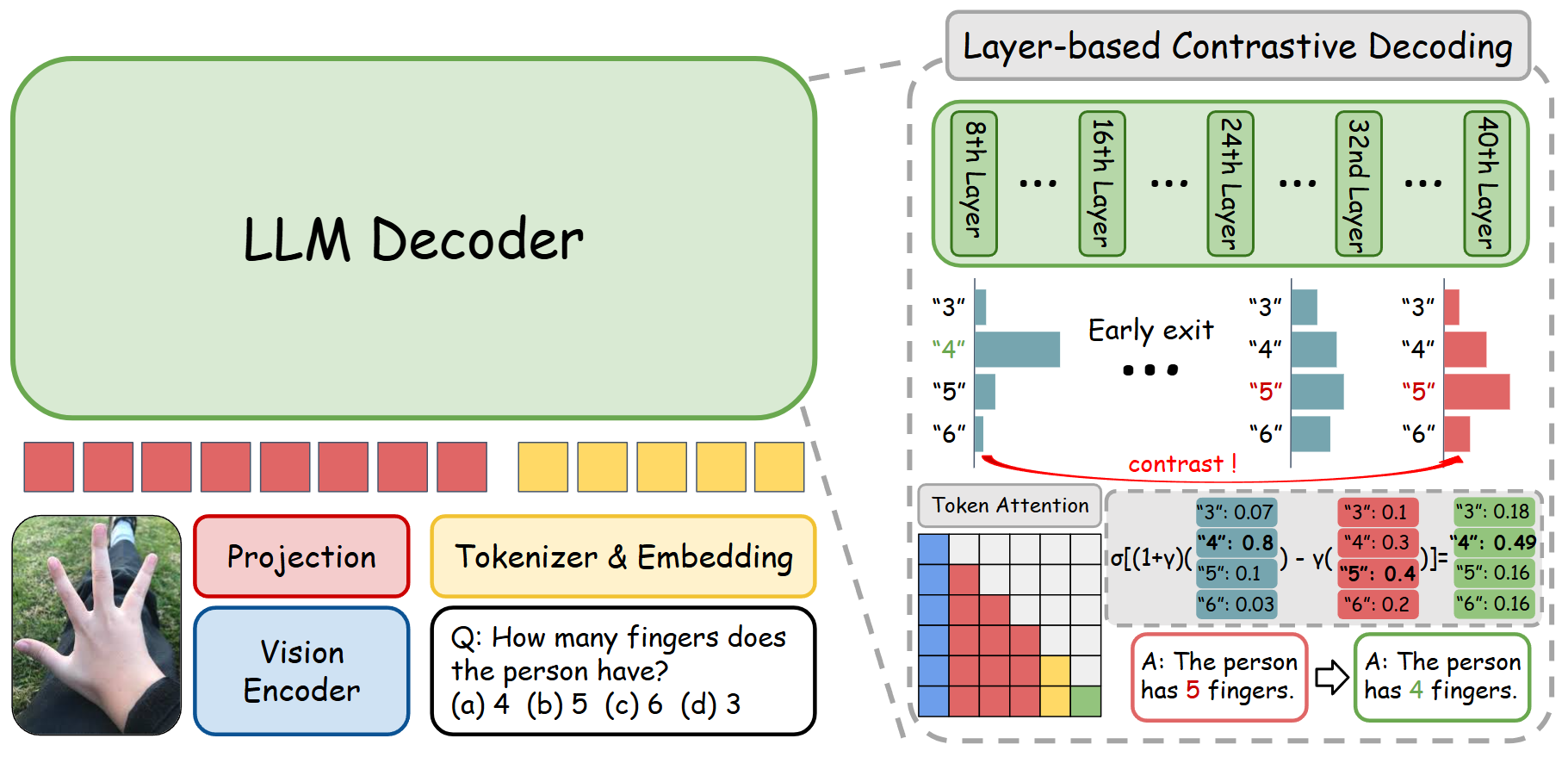
VLMs tend to perform hallucination when the image input conflicts with the LLM decoder knowledge base (common sense).
To resolve this issue, we constructed a small-scale VQA dataset with images involving knowledge conflicts from the Internet or generated with DALL·E 3 for validation, and evaluated 8 state-of-the-art VLMs on the dataset.
We also resolved the knowledge conflicts in LLaVA-1.5 with contrastive decoding.